
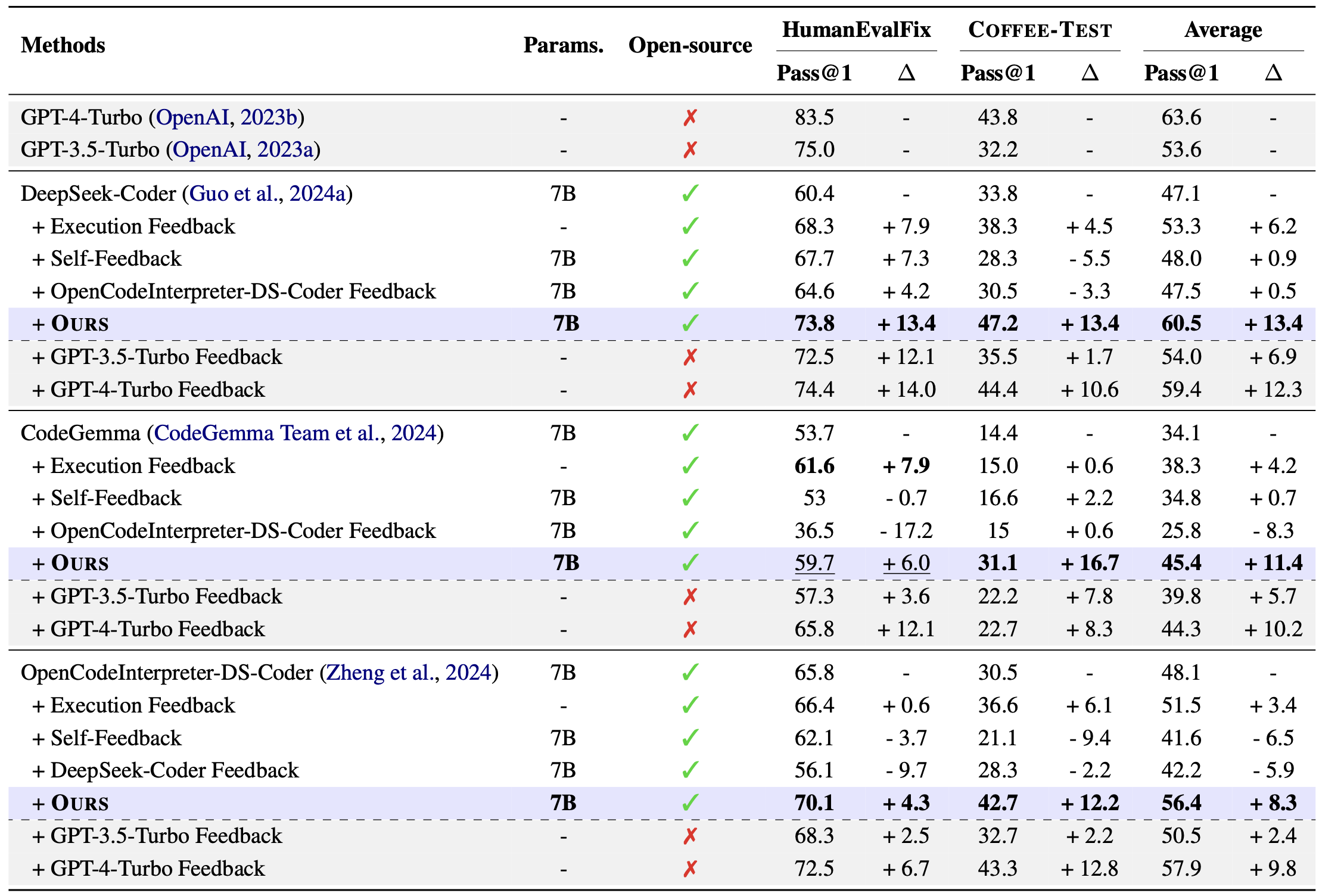
Code editing results of our feedback model trained with Coffee-Gym, i.e., PPO-COFFEEVAL, on HumanEvalFix and COFFEE-Test. We pair our feedback model with an open-source code LLM as the code editor.
♻ [2024-02-21]: We have updated our paper and released the second version of our draft on Arxiv!
🛎[2024-02-22]: We have made our code available on GitHub! Check out our Github repository for more details.
📑[2023-11-19]: We have uploaded the first version of our preprint to arxiv [Link to our paper]
☕[2023-11-11]: We have open-sourced Coffee dataset used in our project named Coffee-Gym.
This paper presents COFFEE-GYM, a comprehensive RL environment for training models that provide feedback on code editing. COFFEE-GYM includes two major components: (1) COFFEE, a dataset containing humans' codeedit traces for coding questions and machine-written feedback for editing erroneous code; (2) COFFEEEVAL, a reward function that faithfully reflects the helpfulness of feedback by assess-ing the performance of the revised code in unittests. With them, COFFEE-GYM addresses theunavailability of high-quality datasets for train-ing feedback models with RL, and providesmore accurate rewards than the SOTA rewardmodel (i.e., GPT-4). By applying COFFEE-GYM, we elicit feedback models that outper-form baselines in enhancing open-source code LLMs' code editing, making them comparablewith closed-source LLMs. We make the datasetand the model checkpoint publicly available.
 COFFEE: Human-written Code Edit Traces with Annotated Pairwise Feedback
COFFEE: Human-written Code Edit Traces with Annotated Pairwise Feedback

An example instance from COFFEE dataset.
We curate ☕️ COFFEE, a dataset of code fixing with feedback, from human-written code edit traces. Coffee consists of problems of diverse levels of difficulty, including challenging problems that only human programmers can solve, and provides test cases for reward functions.
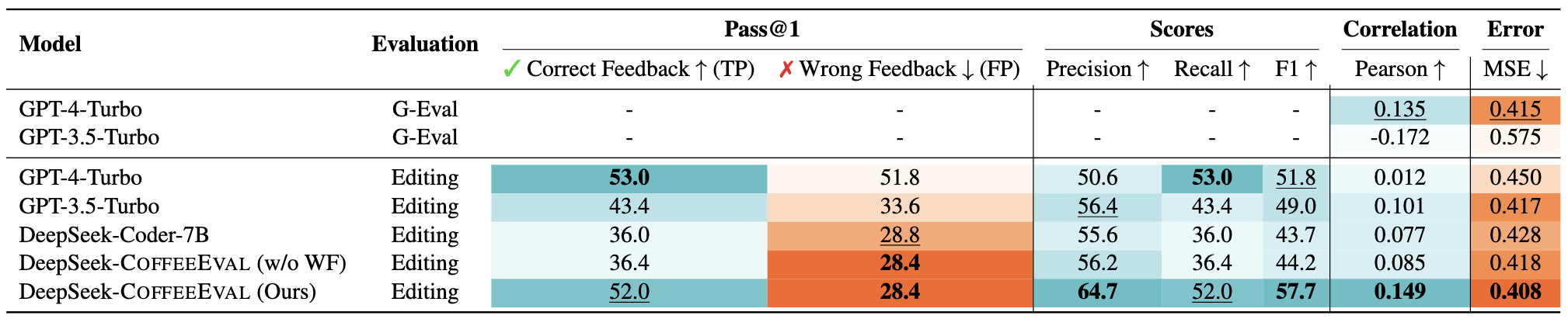
Performance of our evaluation protocol on the test sets of Coffee compared to the baselines. Wrong Feedback is abbreviated as WF due to limited space.
DeepSeek-CoffeeEval achieves higher Pearson correlation and lower MSE than all G-Eval and Editing baselines. In particular, our approach shows even higher correlation than the G-Eval baseline implemented with GPT-4-Turbo. The strong performance of our CoffeeEval validates its effectiveness in assessing the quality of NL feedback in the code editing task.
Code editing results of our feedback model trained with Coffee-Gym, i.e., PPO-COFFEEVAL, on HumanEvalFix and COFFEE-Test. We pair our feedback model with an open-source code LLM as the code editor.
@article{Anonymized,
title={COFFEE-GYM: An Environment for Evaluating and ImprovingNatural Language Feedback on Erroneous Code},
author={Anonymized},
journal={Anonymized},
year={2024}
}